Understanding Hadoop. HDFS
An entry point for those who want to understand Hadoop and its components

Intro
There are many different technologies in the world of Big Data, and it is quite easy to get lost in them.
However, it is good to understand one of them to understand the others.
In this article, I want to provide an easy-to-understand entry point to Hadoop that will help people new to the Big Data world.
When planning this article, I thought I could fit all the information into one article, but I have concluded that it is easier to break this topic into several articles.
So today I will tell you about HDFS and the basic terms you should know.
Hadoop Zoo
Before jumping into HDFS, it’s important to understand the big picture of Hadoop and its components.
Hadoop is a framework that is used to effectively store data in distributed manners and process them in parallel.
So basically Hadoop is not one program is a family of related programs that help (1) store and (2) process data.
In addition, Hadoop is scalable, fault-tolerant, and highly available.
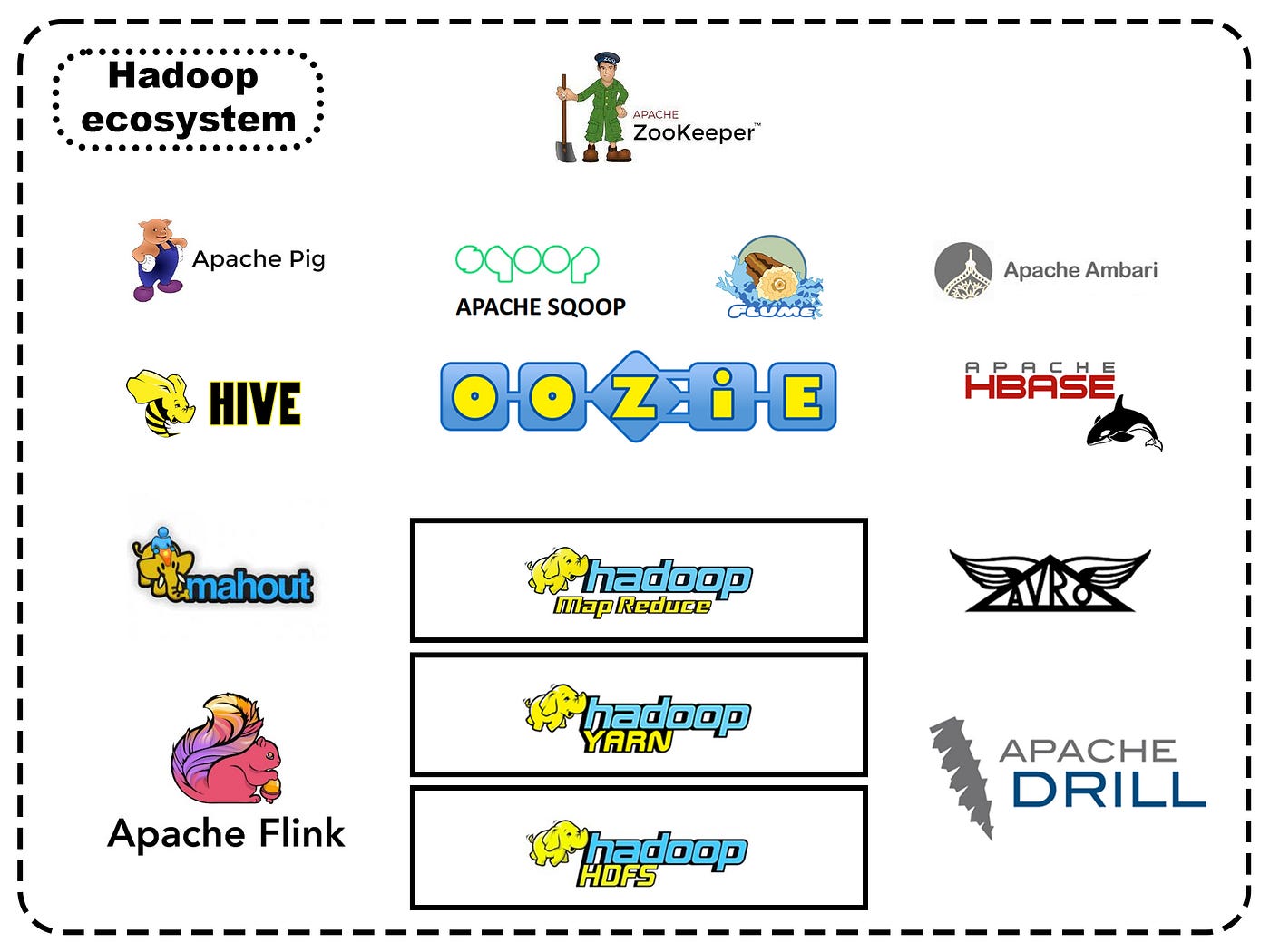
There are many projects around Hadoop, but we will focus on the core (projects in the rectangles).
Hadoop HDFS — Hadoop distributed file system
Hadoop Yarn — Cluster resource management
Hadoop MapReduce — Data processing engine
Hadoop HDFS
HDFS is a distributed, fault-tolerant, highly available file system that stores large amounts of structured and unstructured data in blocks.
It is important to understand that HDFS in general does not work on a single computer but a cluster of commodity hardware.
Commodity hardware is a computer device that is generally economical, interchangeable, and widely available with other hardware of its sort

A node is a separate machine (like your computer) with some CPU, Memory, RAM, and disk space.
A rack is a combination of several nodes which are closely stored together and all nodes are connected to the same Switch (represented by the dashed line in the figure above).
A cluster is a combination of racks under one network. And it works just like your computer but in a distributed manner, meaning that every node process a different piece of information on its own.
Let’s hop up to the main components.
Namenode and Datanodes
HDFS uses a master/worker architecture.
This means that one machine (the master) stores the metadata of all files and controls the writing and reading of these files on the worker machines, while the workers in turn are responsible for the storage/read/write operations themselves.
Metadata represents data about data.
They provide information about the size, access, and physical location of the data

A Namenode (shown in yellow in the diagram above) is usually a machine with more CPU, RAM, and disk space.
It is connected to Datanodes and gives commands to read or write client data.
Namenode does not store customer data, but only stores data where that data is located on the Datanodes (metadata).
- It’s a data
- No. Much more better…It is a data of a data.
Datanodes (shown in blue in the diagram above), in turn, are responsible for writing and reading files, as well as for their reliable storage.
Datanodes are commodity hardware and work together in a cluster to ensure reliable and fault-tolerant operation. They communicate with Namenode and provide all the necessary information about the files they store.
Part of the Cluster, Part of the Rack
I know everything may look a little confusing now, but don’t worry, we will sort it all out.
Now the main thing is to understand that Namenode is responsible for the “work of the head”:
• Remember where the data is stored
• Give a command to record data, as well as to read it
And Datanodes are responsible for the “physical work”:
• Execute Namenode’s commands to write and read files, as well as their reliable and fault-tolerance storage
In the next chapter, we’ll see how data is actually stored and figure out what fault tolerance is and how HDFS provides it.
Blocks
When we store our data in HDFS they will be divided into blocks.
By default, one block is 128 MB

The image above shows a file, let’s say it is 400 MB, there is a certain text of the song “Never Fade Away”.
When we save this file on HDFS, the file is divided into blocks, each block will have a part of the information from the document, with a default block value of 128 MB.
In our case, there will be 4 blocks, three of them will have 128 MB, and the last one will have 16 MB.
(128 MB + 128 MB + 128 MB + 16 MB = 400 MB)
Blocks are distributed across different Datanodes and the Namenode stores metadata about the location of the blocks.
Block Replication
To achieve fault tolerance, each block is duplicated. So when we lose one block, we can use another one.
By default, the Replication Factor for Hadoop is set to 3
Rack Awareness
Now that we’ve covered the main components, let’s move on to the basic concepts.
As we said earlier, HDFS is highly available, fault-tolerant, and reliable.
HDFS creates replicas of file blocks depending on the replication factor and stores them on different machines.
Fault tolerance refers to the ability of the system to work or operate even in case of unfavorable conditions
To reduce network traffic when reading/writing a file, the Namenode selects the nearest Datanode to service the client’s read/write request.
The Namenode maintains the rack IDs of each Datanode to retrieve this rack information.
Selecting the nearest Datanode based on rack information is called Rack Awareness.
Reasons for Rack Awareness:
- Reducing network traffic when reading/writing files improves cluster performance
- To achieve fault tolerance even when the rack fails
- Achieve high data availability so that data is available even in adverse conditions
- To reduce latency
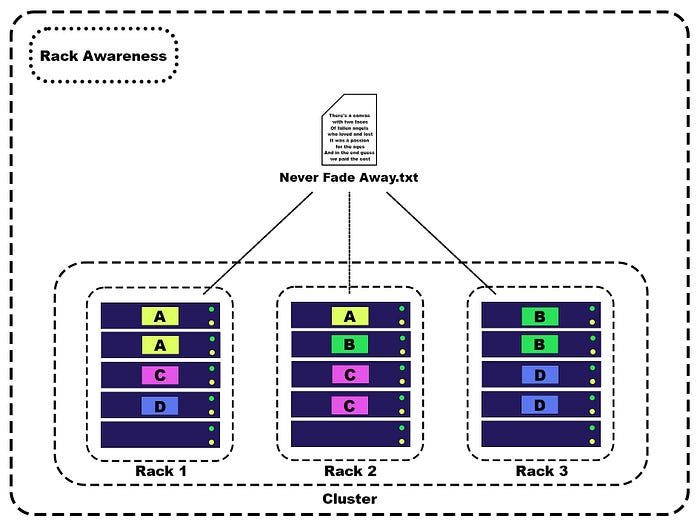
So, let’s see how it works.
In the image above we see the same file as before, it is split into 4 blocks and they are replicated, so now we have three blocks per block.
In the beginning, one block is written on the first node,
then to ensure fault tolerance (if a node cannot continue to work) this block is replicated to the nearest node in the same rack.
There is always a possibility that the rack will also fail (lose the network or something) for this, we store the next copy of our blocks on another rack.
Why can’t all blocks be saved in different racks?
The problem lies in bandwidth and latency.
Storing a block on one rack provides higher bandwidth and lower latency because they are all on the same network and opposite if we store blocks on different racks, we will have lower bandwidth and higher latency because the racks will use an external network.
Read and Write operations

When we want to read a file from HDFS we need to do the next steps:
- Open HDFS.
- HDFS inner object (called FileSystem) calls the Namenode to determine the location of the blocks in the file.
For each block, it returns the addresses of the Datanodes that have a copy of that block. - When we got the locations, we invoke the operation read.
HDFS looks for the closest Datanode and reads the first block.
After that data is streamed from the Datanode back to the client.
This operation calls repeatedly until the end of the block is reached. - After the block was completely read the connection with the Datanode will be closed.
And operations 3–4 will start over for the next blocks.
From the client’s point of view is just reading a continuous stream.

Next, let’s look at how files are written to HDFS:
- The client creates a file.
- An internal HDFS object calls a Namenode to create a new file in the file system namespace.
Namenode performs various checks to ensure that the file does not already exist and that the client has the right permissions to create the file.
If everything is okay, a record of the new file will be created, otherwise, an IOException will be thrown. - The data will be split into packets, which will be written to an internal queue called the data queue.
Namenode will allocate new blocks by picking a list of suitable Datanodes to store the replicas.
The list of Datanodes forms a pipeline and we will stream the packets to the first Datanode in the pipeline, which stores each packet and forwards it to the next Datanode in the pipeline. - There is another internal queue of packets that are waiting to be acknowledged by Datanodes, called the ack queue.
A packet will be removed from the ack queue only when it has been acknowledged by all the Datanodes in the pipeline. - When we have finished writing data, we close the stream.
This action flushes all the remaining packets to the Datanode pipeline and waits for acknowledgments. - After that, we contact the Namenode to signal that the file is completed.
Fs-image and edit logs
Before we start reading about the Secondary Namenode, there are a few more components of HDFS that need to be understood, namely fs-image and edit logs.
Fs-Image is a file stored in the OS file system that contains the full directory structure (namespace) of HDFS, detailing where data is located in data blocks and which blocks are stored on which node.
When we write, delete or update files, the fs-image is not updated because writing the fs-image file, which can be up to gigabytes in size, will be very slow. For this purpose, we have edit logs.
Edit Logs are records of the changes since the last Fs-Image was created.
It is a transaction log that records the changes in the HDFS file system or any action performed on the HDFS cluster such as the addition of a new block, replication, deletion, etc.
Secondary Namenode
Namenode merges all edit logs into updated fs-image only after startup.
Since a number of edit logs may be unbounded it will take a lot of time to apply all edit records on the last saved copy of fs-image.
During this time, the filesystem would be offline, which is generally undesirable.
The solution is to run the Secondary Namenode, whose purpose is to produce checkpoints of the primary’s in-memory filesystem metadata.

It works as follows:
- The Secondary Namenode retrieves the latest fs-image and edits files from the Namenode.
- The Secondary Namenode loads fs-image into memory applies each transaction from edits, then creates a new merged fs-image file.
- The new fs-image is sent back to the Namenode and saved as a temporary .ckpt file.
- The Namenode renames the temporary fs-image to make it available.
Also if Namenode is failed, file system metadata can be recovered from the last saved Fs-image on the Secondary Namenode but Secondary Namenode cannot take the primary Namenode functionality.
High Availability
The combination of replicas and the use of a Secondary Namenode protects us from data loss, but it does not guarantee us high availability.
High availability is the ability of a system to operate continuously without failure for a designated period
The Namenode is still a single point of failure (SPOF). This means that if it goes down, we will not be able to operate the system.
Of course, it can be recovered from the Secondary Namenode, but we won’t be able to work with our data for a while.
Hadoop 2.x eliminates this bottleneck by adding support for HDFS High availability. This feature supports a passive Standby Namenode. In the event of the failure of the active Namenode, Standby takes over its duties to continue servicing client requests without a significant interruption.
Conclusion
In this article, we have covered the basic components and concepts of HDFS.
Of course, it would not be possible to fit everything in one article, but I hope that you now have an idea of what HDFS is and how it works, and this knowledge will allow you to more easily understand and study this technology more deeply.
I hope it helped you and you got the information you needed.
Thank you for reading.
See you!